Gradient is one the key ingredients when it comes to optimization. In some cases, one might employ second order methods, i.e. using Hessian; however, it is not common in machine learning to use such methods because we simply have too many variables.
In this article, I am going to talk about the conjugate gradient method for optimizing quadratic functions, i.e.
f(x)x∗=21xTAx−bTx=xargminf(x)
where A∈Rn×n is symmetric positive semi-definite and b∈Rn. A and b are coefficients of the functions. In this setting, the method ensures that we will converge to the solution within n steps, where n is the dimensions of variables.
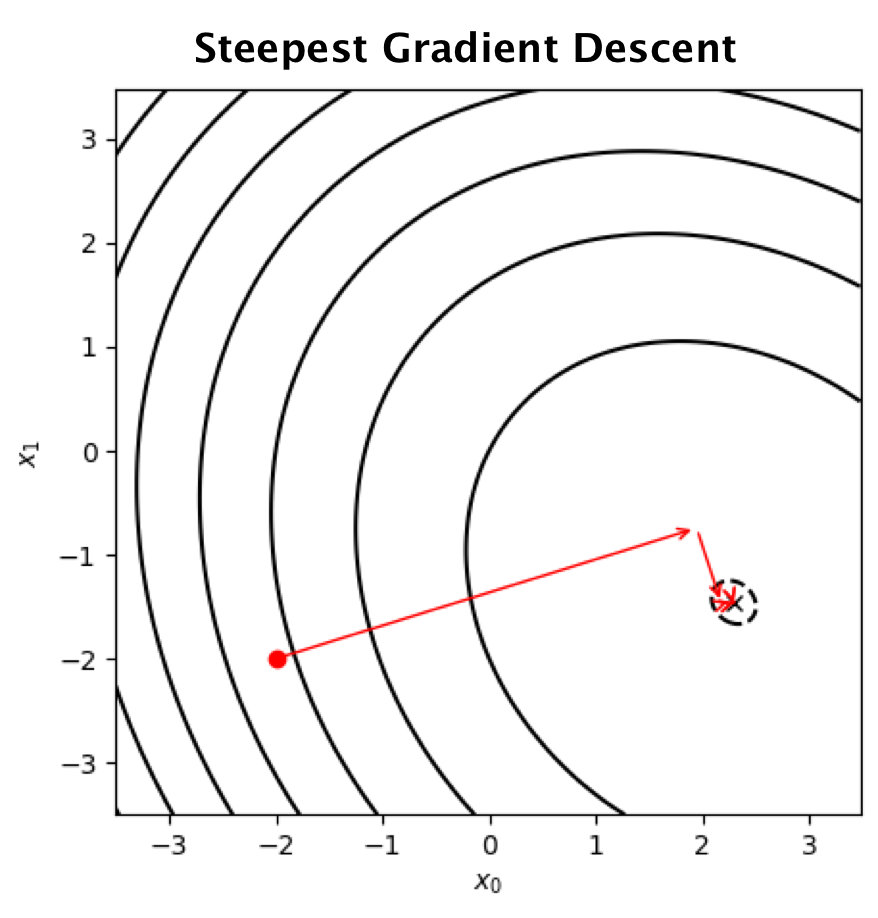
Steepest Gradient Descent
Let first revisit the gradient descent method. The method iteratively finds f(x)'s possible minimizer x^ by using
xi+1=xi−αt∇f(xi),
where αi is a learning rate at each iteration and ∇f(xi) denotes ∇f(x) evaluated at xi. Noting that, in general, the gradient descent update does not guarantee that x^=x∗, i.e. x^ might be at some local optima.
Naively, one can set αi at some constate value, but a better way might be to choose the value based on the situation at hand. Consider performing a line search at each iteration to find the best value. In other word, we seek αi by finding the first derivative at f(xi+1) and set it to zero:
This derivation tells us that, along the search direction ∇f(xt), the optimal value of αt is the one leading to the location that two gradients are orthogonal. Solving the equation above for α
which simply tells us how far we are from the answer. In contrast, residual at each step is the difference between the minimum value and our current value:
ri=b−Axi=Ax∗−Axi=Aei
Combining the definitions of error and residual yields
ri=b−Axi=Ax∗−Axi=A(x∗−xi)=Aei.
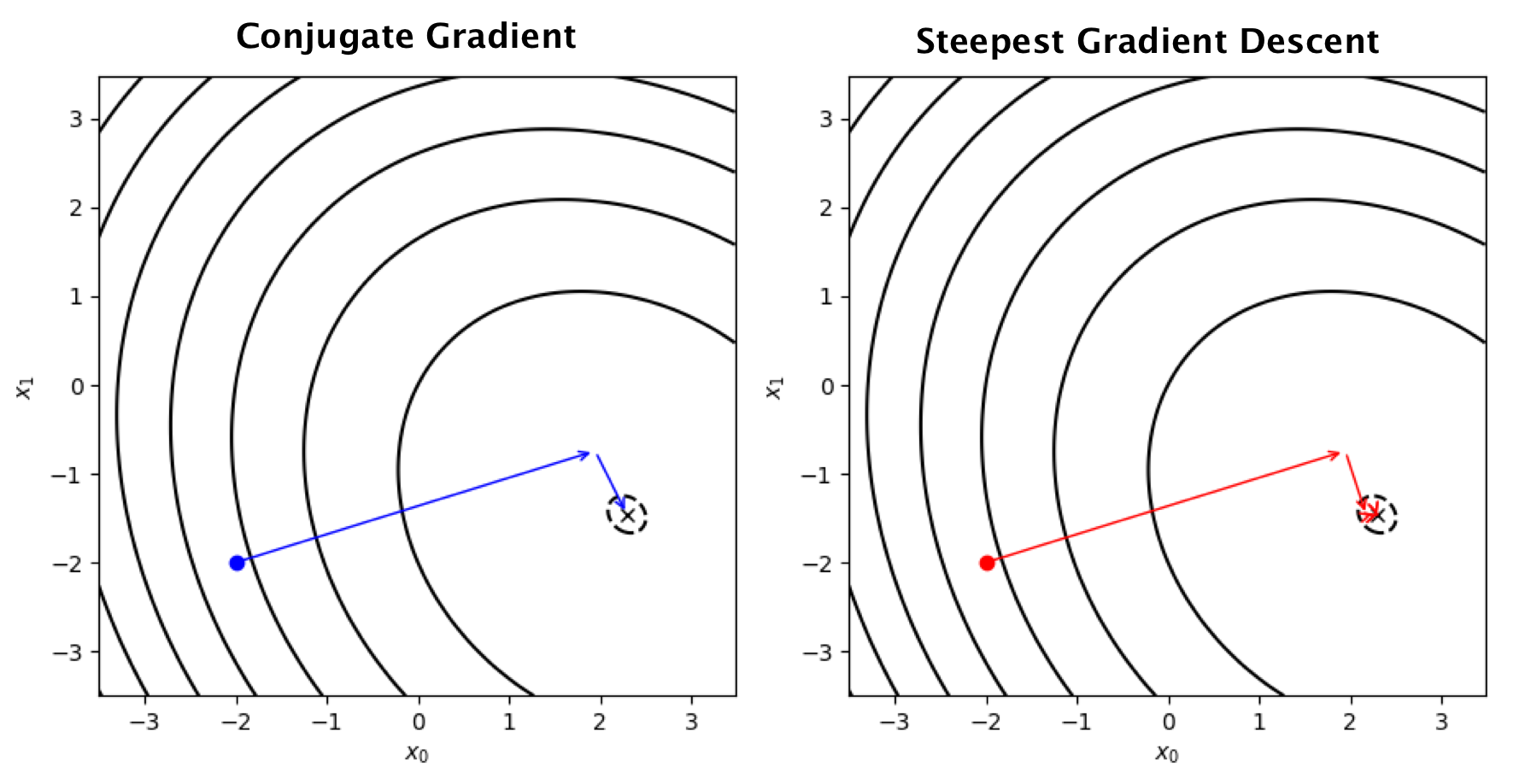
Conjugate Directions
One problem of Steepest Descent is that every move inteferes previous moves; hence slow convergence. It would be good to have search directions that do not affect each other.
Consider an update
xi+1=xi+αidi,
where αi is update step and di is a search direction. We can to find x^ in n updates (using n directions d1,…,dn), if these directions are orthogonal to each other
d0⊥d1⊥d2⊥⋯⊥dn.
Therefore, the error at each step et is also orthogonal to previous search directions, e.g.
However, as we do not know x∗ so do αi. Instead of requiring orthogonality diTdj, we construct search directions that are orthogonal under the transformation of the matrix A. In other word, we want di and dj to be A-Conjugate (Orthogonal):
diTAdj=0.
If we find the minimum along the search direction di, we have
Now, αi is computable. By construction, taking the αidi step ensures that diTri+1=0. The only thing that we need to find is the set of A-conjugate search directions {di}.
Gram-Schmidt Conjugation
Consider linearly independent vectors u0,u1,…,uj−1. One can construct A-orthogonal basis {d0,d1,…,dj−1} from these vectors using (Conjugate) Gram-Schmidt Process
dj=uj−k=1∑j−1βjkdk,
where βjk is a scaling factor that we seek to find. One issue immediately arises: How should one construct uj? It turns out that we can use rj as uj (Proof). Therefore, we have
dj=rj−k=1∑j−1βjkdk.(1)
Based on our conjugatecy requirement, this new direction dj should be A-orthogonal to all previous search directions di for i<j, hence
The derivation above shows how we construct A-orthogonal search directions. However, another problem is that the contruction uses all previous search directions in the process, hence large memory complexity. Fortunately, we can make this memory aspect more efficient.
Consider that diTrj=0 for ∀i<j (Proof). Multiplying rjT to Equation (1) yields