Artificial neural networks (ANNs) have become a power horse of many intelligent systems. This success is party due to its automatically way to learn representation for solving the task at hand. Consider an image classification task, previous approaches relied on hand-crafted features such as SIFT to build a program that can solve the task well. Unlike the previous approaches, artificial neural networks discover appropriate features for the task themselves through learning (i.e. optimization using backpropagation and gradient descent).
What do the latent representations of ANNs represent?
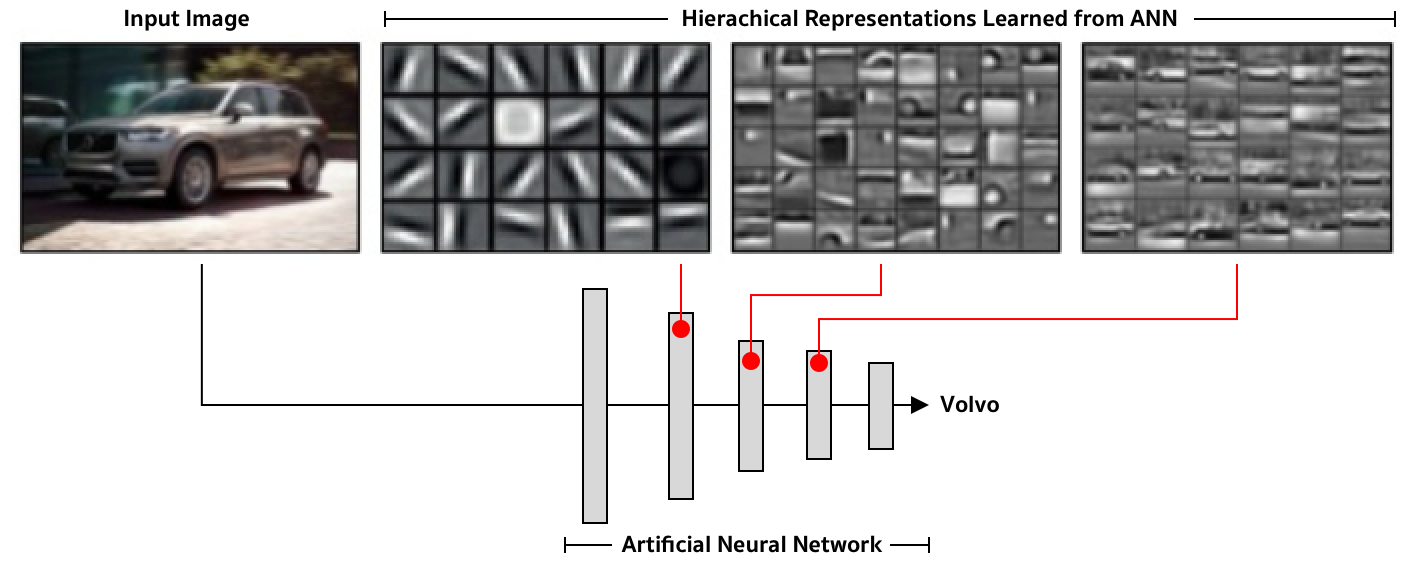
Many works have investigated what these representations of ANNs represent. For example, Lee et al. (2011) have found that early layers would learn to detect simple objects such as edges; the complexity of objects or concepts increases progressively as we move towards the last layer. In other words, the ANN learns to extract hierachical representations, progressively detacting simple to complex features. Nevertheless, it is worth noting that each coordinate of these latent space encodes certain meanings, which may or may not align with our intuition.
Another direction that we can investigate this phenomenon is to look at neightbours in these space. For example, we can use an image, take its activation at a certain layer, and then find the neighbour points (i.e. other images' activation). Most of the case, we will get these neighbour points are the images look visually to the image that we query.

Concept Activation Vector
Although there is no clear interpretation of these latent spaces, one can leverage the fact that similar samples will be close together in this spaces for building an interpretability method that can explain ANNs with human-understandable concepts.
Given a trained image classifier , Kim et al. (2018) propose to build a linear classifier based on the latent representation of this classifier using two sets of images: one contains samples with the concept of interest and the other one is the complement (or something else). Geometrically, this linear classifier is a hyperplane in a -dimension space represented by a normal vector , called Concept Activation Vector.
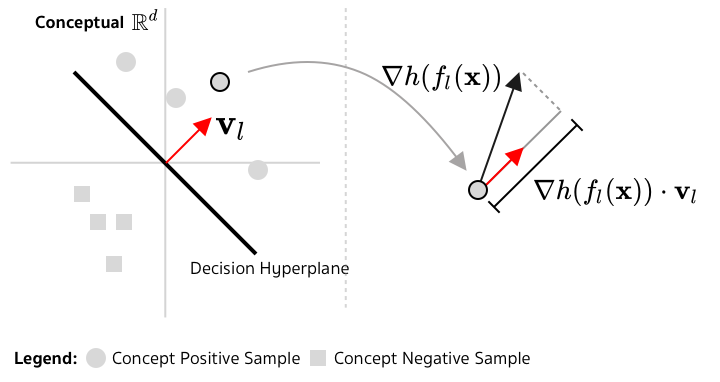
To quantify whether a certain image aligns with a certain concept , we can measure how sensitive is when the image's latent representation slighly moves along . Let denote the function mapping from to the output of . Mathematically, this quantity is:
which is the directional derivative. If we assume that , this is the orthogonal projection of on .
Appendix
A nice tutorial about direction derivative: KhanAcademy's Directional Derivative.